private static int hash(int h) { // Spread bits to regularize both segment and index locations, // using variant of single-word Wang/Jenkins hash. h += (h << 15) ^ 0xffffcd7d; h ^= (h >>> 10); h += (h << 3); h ^= (h >>> 6); h += (h << 2) + (h << 14); return h ^ (h >>> 16); }
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable { /** * Mask value for indexing into segments. The upper bits of a * key's hash code are used to choose the segment. */ final int segmentMask;
/** * Shift value for indexing within segments. */ final int segmentShift;
/** * The segments, each of which is a specialized hash table */ final Segment<K,V>[] segments; }
static final class Segment<K,V> extends ReentrantLock implements Serializable { private static final long serialVersionUID = 2249069246763182397L; /** * The number of elements in this segment's region. */ transient volatile int count;
/** * Number of updates that alter the size of the table. This is * used during bulk-read methods to make sure they see a * consistent snapshot: If modCounts change during a traversal * of segments computing size or checking containsValue, then * we might have an inconsistent view of state so (usually) * must retry. */ transient int modCount;
/** * The table is rehashed when its size exceeds this threshold. * (The value of this field is always <tt>(int)(capacity * * loadFactor)</tt>.) */ transient int threshold;
/** * The per-segment table. */ transient volatile HashEntry<K,V>[] table;
/** * The load factor for the hash table. Even though this value * is same for all segments, it is replicated to avoid needing * links to outer object. * @serial */ final float loadFactor; }
V remove(Object key, int hash, Object value) { lock(); try { int c = count - 1; HashEntry<K,V>[] tab = table; int index = hash & (tab.length - 1); HashEntry<K,V> first = tab[index]; HashEntry<K,V> e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next;
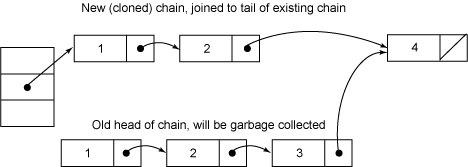
V oldValue = null; if (e != null) { V v = e.value; if (value == null || value.equals(v)) { oldValue = v; // All entries following removed node can stay // in list, but all preceding ones need to be // cloned. ++modCount; HashEntry<K,V> newFirst = e.next; for (HashEntry<K,V> p = first; p != e; p = p.next) newFirst = new HashEntry<K,V>(p.key, p.hash, newFirst, p.value); tab[index] = newFirst; count = c; // write-volatile } } return oldValue; } finally { unlock(); } }
V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); try { int c = count; if (c++ > threshold) // ensure capacity rehash(); HashEntry<K,V>[] tab = table; int index = hash & (tab.length - 1); HashEntry<K,V> first = tab[index]; HashEntry<K,V> e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next;
V oldValue; if (e != null) { oldValue = e.value; if (!onlyIfAbsent) e.value = value; } else { oldValue = null; ++modCount; tab[index] = new HashEntry<K,V>(key, hash, first, value); count = c; // write-volatile } return oldValue; } finally { unlock(); } }
V get(Object key, int hash) { if (count != 0) { // read-volatile HashEntry<K,V> e = getFirst(hash); while (e != null) { if (e.hash == hash && key.equals(e.key)) { V v = e.value; if (v != null) return v; return readValueUnderLock(e); // recheck } e = e.next; } } return null; }
最后,如果找到了所求的结点,判断它的值如果非空就直接返回,否则在有锁的状态下再读一次。这似乎有些费解,理论上结点的值不可能为空,这是因为put的时候就进行了判断,如果为空就要抛NullPointerException。空值的唯一源头就是HashEntry中的默认值,因为HashEntry中的value不是final的,非同步读取有可能读取到空值。仔细看下put操作的语句:tab[index] = new HashEntry
public int size() { final Segment<K,V>[] segments = this.segments; long sum = 0; long check = 0; int[] mc = new int[segments.length]; // Try a few times to get accurate count. On failure due to // continuous async changes in table, resort to locking. for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) { check = 0; sum = 0; int mcsum = 0; for (int i = 0; i < segments.length; ++i) { sum += segments[i].count; mcsum += mc[i] = segments[i].modCount; } if (mcsum != 0) { for (int i = 0; i < segments.length; ++i) { check += segments[i].count; if (mc[i] != segments[i].modCount) { check = -1; // force retry break; } } } if (check == sum) break; } if (check != sum) { // Resort to locking all segments sum = 0; for (int i = 0; i < segments.length; ++i) segments[i].lock(); for (int i = 0; i < segments.length; ++i) sum += segments[i].count; for (int i = 0; i < segments.length; ++i) segments[i].unlock(); } if (sum > Integer.MAX_VALUE) return Integer.MAX_VALUE; else return (int)sum; }
public boolean containsValue(Object value) { if (value == null) throw new NullPointerException();
// See explanation of modCount use above
final Segment<K,V>[] segments = this.segments; int[] mc = new int[segments.length];
// Try a few times without locking for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) { int sum = 0; int mcsum = 0; for (int i = 0; i < segments.length; ++i) { int c = segments[i].count; mcsum += mc[i] = segments[i].modCount; if (segments[i].containsValue(value)) return true; } boolean cleanSweep = true; if (mcsum != 0) { for (int i = 0; i < segments.length; ++i) { int c = segments[i].count; if (mc[i] != segments[i].modCount) { cleanSweep = false; break; } } } if (cleanSweep) return false; } // Resort to locking all segments for (int i = 0; i < segments.length; ++i) segments[i].lock(); boolean found = false; try { for (int i = 0; i < segments.length; ++i) { if (segments[i].containsValue(value)) { found = true; break; } } } finally { for (int i = 0; i < segments.length; ++i) segments[i].unlock(); } return found; }
同样注意内层的第一个for循环,里面有语句int c = segments[i].count; 但是c却从来没有被使用过,即使如此,编译器也不能做优化将这条语句去掉,因为存在对volatile变量count的读取,这条语句存在的唯一目的就是保证segments[i].modCount读取到几乎最新的值。关于containsValue方法的其它部分就不分析了,它和size方法差不多。