csvJava中csv文件读写分析
代长亚一、txt、csv、tsv文件
txt、csv、tsv都属于文本文件
| 文件类型 |
英文全称 |
名称 |
分隔符 |
描述 |
| txt |
text |
文本类型 |
没有明确要求 |
可以有分隔符,也可以没有 |
| csv |
Comma-separated values |
逗号分隔值类型 |
半角逗号:',' |
csv是txt的特殊类型 |
| tsv |
Tab-separated values |
制表符分隔值 |
制表符:'\t' |
tsv是txt的特殊类型 |
csv又有叫做Char-separated values(字符分隔值类型),通过字符值进行分隔。
但因为半角逗号在数据中出现的的可能性比较大,所以经常会使用文本包装符来标识逗号为数据中的一部分,或者直接使用其它特殊符号作为分隔符。
二、csv文件规范
- 每一行记录位于一个单独的行上,用回车换行符CRLF(\r\n)分割。
- 文件中的最后一行记录可以有结尾回车换行符,也可以没有。
- 第一行可以存在一个可选的标题头,格式和普通记录行的格式一样。标题头要包含文件记录字段对应的名称,应该有和记录字段一样的数量。
- 在标题头行和普通行每行记录中,会存在一个或多个由半角逗号(,)分隔的字段。整个文件中每行应包含相同数量的字段,空格也是字段的一部分,不应被忽略。每一行记录最后一个字段后不能跟逗号。(通常用逗号分隔,也有其他字符分隔的CSV,需事先约定)
- 每个字段可用也可不用半角双引号(“)(文本包装符)括起来(如Microsoft的Excel就根本不用双引号)。如果字段没有用引号括起来,那么该字段内部不能出现双引号字符。
- 字段中若包含回车换行符、双引号或者逗号,该字段需要用双引号括起来。
- 如果用双引号括字段,那么出现在字段内的双引号前必须再加一个双引号进行转义。
三、csv使用场景
csv文件经常用于导出大批量数据(csv比excel更轻量级,更适合大批量数据)。
csv与excel对比:
- csv只能用于存储纯文本内容,excel不仅支持纯文本内容还支持二进制数据
- csv可以看做是excel的轻量级简单版实现,excel比csv更加强大
- csv文件可以被excel软件直接打开,csv文件一般用于表格数据的传输
四、Java中的csv类库
java中的csv的类库主要有以下几类:
- javacsv:javacsv在2014-12-10就不维护了
- opencsv:opencsv是apache的项目,至今仍在维护
1. javacsv
2. opencsv
opencsv是一个用Java来分析和生成csv文件的框架。通常用来bean的写入csv文件和从csv文件读出bean,并支持注解的方式。
maven依赖:
xml
复制代码
1
2
3
4
5
| <dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.7.0</version>
</dependency>
|
写入器
| 名称 |
描述 |
| CSVWriter |
简单的CSV写入器 |
| CSVParserWriter |
通过CSVParser解析数据的写入器 |
| StatefulBeanToCsv |
直接将bean写入CSV的写入器 |
读取器
| 名称 |
描述 |
| CSVReader |
简单的CSV读取器 |
| CsvToBean |
CSV读取为bean的读取器 |
| CSVReaderHeaderAware |
|
解析器
| 名称 |
描述 |
| CSVParser |
简单的CSV解析器 |
| RFC4180Parser |
基于RFC4180规范的解析器 |
注解
| 注解 |
描述 |
主要属性 |
| @CsvBindByName |
按表头名称绑定 |
required:必须字段,默认为false.该字段为空抛异常 column:对象列标题名称 |
| @CsvBindByPosition |
按位置绑定 |
required:必须字段,默认为false.该字段为空抛异常 position:位置索引 |
| @CsvCustomBindByName |
与CsvBindByName相同,但必须提供自己的数据转换类 |
required:必须字段,默认为false.该字段为空抛异常 column:对象列标题名称 converter:转换器 |
| @CsvCustomBindByPosition |
与CsvBindByPosition相同,但必须提供自己的数据转换类 |
required:必须字段,默认为false.该字段为空抛异常 column:对象列标题名称 converter:转换器 |
| @CsvBindAndJoinByName |
应用于MultiValuedMap集合类型的bean字段,通过标题名称绑定 |
required:必须字段,默认为false.该字段为空抛异常 column:对象列标题名称 converter:转换器 mapType:集合类型 elementTyp:元素类型 |
| @CsvBindAndJoinByPosition |
应用于MultiValuedMap集合类型的bean字段,通过位置索引绑定 |
required:必须字段,默认为false.该字段为空抛异常 position:位置索引 converter:转换器 mapType:集合类型 elementTyp:元素类型 |
| @CsvBindAndSplitByName |
应用于Collection集合类型的bean字段,通过标题名称绑定 |
required:必须字段,默认为false.该字段为空抛异常 column:对象列标题名称 converter:转换器 mapType:集合类型 elementTyp:元素类型 splitOn: |
| @CsvBindAndSplitByPosition |
应用于Collection集合类型的bean字段,通过位置索引绑定 |
required:必须字段,默认为false.该字段为空抛异常 position:位置索引 converter:转换器 mapType:集合类型 elementTyp:元素类型 splitOn: |
| @CsvDate |
应用于日期/时间类型的bean字段,与上面相关的绑定注解结合使用 |
value:日期格式,例如:yyyy-MM-dd |
| @CsvNumber |
应用于数字类型的bean字段,与上面相关的绑定注解结合使用 |
value:数字格式,例如:000.### |
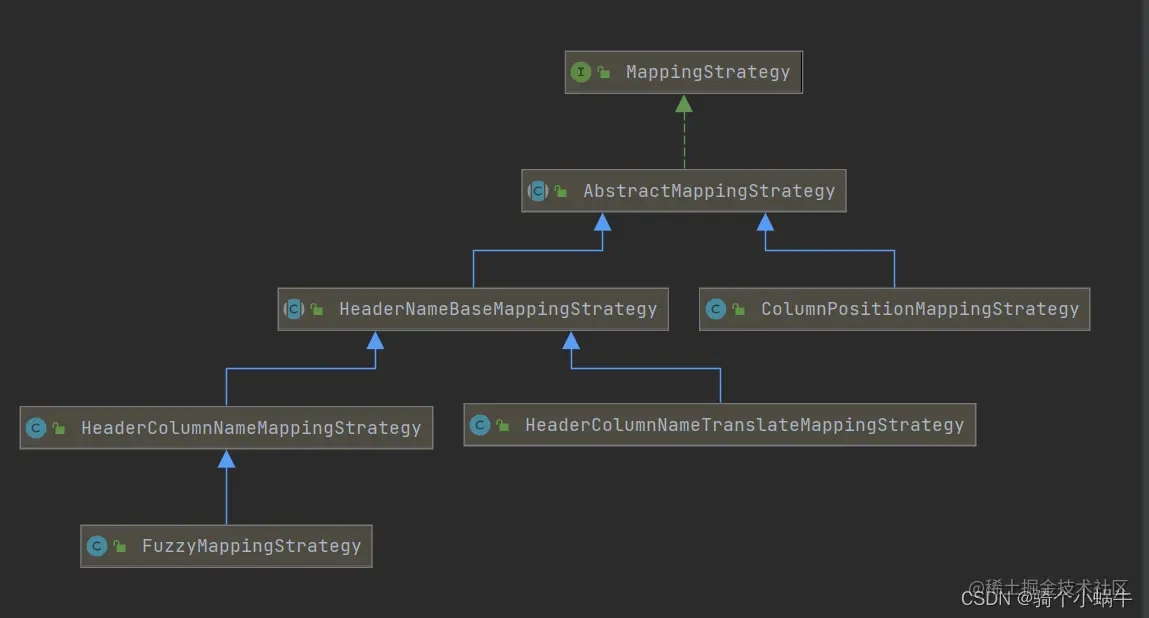
映射策略

| 名称 |
描述 |
重要方法 |
方法描述 |
| ColumnPositionMappingStrategy |
列位置映射策略,用于没有头文件(标题行)的文件 |
setColumnMapping(String… columnMapping |
设置要映射的列名集合,集合下标即为列写入顺序 |
| HeaderColumnNameMappingStrategy |
标题列名称映射策略, |
setColumnOrderOnWrite(Comparator writeOrder) |
通过比较器,设置列写入顺序 |
| HeaderColumnNameTranslateMappingStrategy |
标题列名称翻译映射策略 bean的属性名可以与csv列头不一样,通过指定map来映射。 |
setColumnMapping(Map<String, String> columnMapping) |
设置标题名与列名的映射 |
| FuzzyMappingStrategy |
|
|
|
① ColumnPositionMappingStrategy
使用该映射策略需要csv文件没有标题行。该策略通过设置列的下标位置来指定列的顺序,有两种方式来设置列的下标:
- 通过CsvBindByPosition、CsvCustomBindByPosition、CsvBindAndJoinByPosition、CsvBindAndSplitByPosition注解来设置列的下标
- 通过setColumnMapping(String… columnMapping)方法来设置列的下标
② HeaderColumnNameMappingStrategy
该映射策略用于有标题行的csv文件。该策略通过指定比较器来指定列的顺序:
- 通过setColumnOrderOnWrite(Comparator writeOrder)指定比较器
关于标题列的名称:
- 默认使用bean的字段名称大写作为标题列的名称
- 如果使用CsvBindByName、CsvCustomBindByName、CsvBindAndJoinByName、CsvBindAndSplitByName注解的column属性指定列名称,则使用该值,否则使用bean的字段名称大写作为标题列的名称
③ HeaderColumnNameTranslateMappingStrategy
该映射策略用于有标题行的csv文件。该策略通过映射Map来指定标题列名与bean的属性名映射关系。
映射Map的key=标题列名,value=bean的属性名。
需要注意:
- 该映射策略只适用于读取csv文件时,指定标题列名与bean的属性名的映射关系
- 该映射策略不适用于写入csv文件时,指定bean的属性名与标题列名的映射关系(不要误解)
过滤器
| 名称 |
描述 |
| CsvToBeanFilter |
读取时根据过滤规则过滤掉一些行 |
主要方法:boolean allowLine(String[] line)
- 入参中的line表示一行数据的集合
- 返回值为false的这行数据被将被过滤掉
构建器
| 名称 |
描述 |
| CSVWriterBuilder |
CSV写入构建器,构建CSVWriter或CSVParserWriter |
| StatefulBeanToCsvBuilder |
对象写入CSV构建器,构建StatefulBeanToCsv |
| CSVReaderBuilder |
CSV读取构建器,构建CSVReader |
| CsvToBeanBuilder |
CSV读取对象构建器,构建CsvToBean |
| CSVReaderHeaderAwareBuilder |
构建CSVReaderHeaderAware |
| CSVParserBuilder |
CSV解析器构造器,构建CSVParser |
| RFC4180ParserBuilder |
RFC4180解析器构造器,构建RFC4180Parser |
写入方式
User类:
1
2
3
4
5
6
7
8
| @Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String userId;
private String userName;
private String sex;
}
|
User1类:
1
2
3
4
5
6
7
8
9
10
11
| @Data
@NoArgsConstructor
@AllArgsConstructor
public class User1 {
@CsvBindByPosition(position = 0)
public String userId;
@CsvBindByPosition(position = 1)
public String userName;
@CsvBindByPosition(position = 2)
public String sex;
}
|
User2类:
1
2
3
4
5
6
7
8
9
10
11
| @Data
@NoArgsConstructor
@AllArgsConstructor
public class User2 {
@CsvBindByName(column = "用户ID")
public String userId;
@CsvBindByName(column = "用户名")
public String userName;
@CsvBindByName(column = "性别")
public String sex;
}
|
① 简单的写入
CSVWriter的主要参数:
Writer writer:指定需要写入的源文件
char separator:分隔符(默认逗号)
char quotechar:文本边界符(默认双引号)
如果数据中包含分隔符,需要使用文本边界符包裹数据。通常用双引号、单引号或斜杠作为文本边界符
char escapechar:转义字符(默认双引号)
String lineend:行分隔符(默认为\n)
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| /**
* 简单的写入
* @throws Exception
*/
private static void csvWriter() throws Exception {
// 写入位置
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
// 标题行
String[] titleRow = {"用户ID", "用户名", "性别"};
// 数据行
ArrayList<String[]> dataRows = new ArrayList<>();
String[] dataRow1 = {"1", "张三", "男"};
String[] dataRow2 = {"2", "李四", "男"};
String[] dataRow3 = {"3", "翠花", "女"};
dataRows.add(dataRow1);
dataRows.add(dataRow2);
dataRows.add(dataRow3);
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(fileName), Charset.forName("UTF-8"));
// 1. 通过new CSVWriter对象的方式直接创建CSVWriter对象
// CSVWriter csvWriter = new CSVWriter(writer);
// 2. 通过CSVWriterBuilder构造器构建CSVWriter对象
CSVWriter csvWriter = (CSVWriter) new CSVWriterBuilder(writer)
.build();
// 写入标题行
csvWriter.writeNext(titleRow, false);
// 写入数据行
csvWriter.writeAll(dataRows, false);
csvWriter.close();
}
|
1
2
3
4
| 用户ID,用户名,性别
1,张三,男
2,李四,男
3,翠花,女
|
② 基于位置映射的写入
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| /**
* 基于位置映射的写入
* @throws Exception
*/
private static void beanToCsvByPosition() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
List<User> list = new ArrayList<>();
list.add(new User("1", "张三", "男"));
list.add(new User("2", "李四", "男"));
list.add(new User("3", "翠花", "女"));
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(fileName), Charset.forName("UTF-8"));
ColumnPositionMappingStrategy<User> strategy = new ColumnPositionMappingStrategy();
// 未指定的列不写入
String[] columns = new String[] { "userId", "userName", "sex"};
strategy.setColumnMapping(columns);
strategy.setType(User.class);
// 如果需要标题行,可这样写入
// CSVWriter csvWriter = (CSVWriter) new CSVWriterBuilder(writer)
// .build();
// String[] titleRow = {"用户ID", "用户名", "性别"};
// csvWriter.writeNext(titleRow, false);
StatefulBeanToCsv<User> statefulBeanToCsv = new StatefulBeanToCsvBuilder<User>(writer)
.withMappingStrategy(strategy)
.withApplyQuotesToAll(false)
.build();
statefulBeanToCsv.write(list);
writer.close();
}
|
③ 基于CsvBindByPosition注解映射的写入
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| /**
* 基于CsvBindByPosition注解映射的写入
* @throws Exception
*/
private static void beanToCsvByPositionAnnotation() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
List<User1> list = new ArrayList<>();
list.add(new User1("1", "张三", "男"));
list.add(new User1("2", "李四", "男"));
list.add(new User1("3", "翠花", "女"));
// 未使用@CsvBindByPosition注解的列不写入
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(fileName), Charset.forName("UTF-8"));
// 如果需要标题行,可这样写入
// CSVWriter csvWriter = (CSVWriter) new CSVWriterBuilder(writer)
// .build();
// String[] titleRow = {"用户ID", "用户名", "性别"};
// csvWriter.writeNext(titleRow, false);
StatefulBeanToCsv<User1> statefulBeanToCsv = new StatefulBeanToCsvBuilder<User1>(writer)
.withApplyQuotesToAll(false)
.build();
statefulBeanToCsv.write(list);
writer.close();
}
|
④ 基于列名映射的写入
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| /**
* 基于列名映射的写入
* @throws Exception
*/
private static void beanToCsvByName() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
List<User> list = new ArrayList<>();
list.add(new User("1", "张三", "男"));
list.add(new User("2", "李四", "男"));
list.add(new User("3", "翠花", "女"));
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(fileName), Charset.forName("UTF-8"));
// 可通过比较器指定列的顺序
// 标题行的列名默认为bean的字段名大写
HeaderColumnNameMappingStrategy<User> strategy = new HeaderColumnNameMappingStrategy<>();
HashMap<String, Integer> columnOrderMap = new HashMap<>();
columnOrderMap.put("USERID", 1);
columnOrderMap.put("SEX", 10);
columnOrderMap.put("USERNAME", 100);
strategy.setColumnOrderOnWrite(Comparator.comparingInt(column -> (columnOrderMap.getOrDefault(column, 0))));
strategy.setType(User.class);
StatefulBeanToCsv<User> statefulBeanToCsv = new StatefulBeanToCsvBuilder<User>(writer)
.withMappingStrategy(strategy)
.withApplyQuotesToAll(false)
.build();
statefulBeanToCsv.write(list);
writer.close();
}
|
1
2
3
4
| USERID,SEX,USERNAME
1,男,张三
2,男,李四
3,女,翠花
|
⑤ 基于CsvBindByName注解映射的写入
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| /**
* 基于CsvBindByName注解映射的写入
* @throws Exception
*/
private static void beanToCsvByNameAnnotation() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
List<User2> list = new ArrayList<>();
list.add(new User2("1", "张三", "男"));
list.add(new User2("2", "李四", "男"));
list.add(new User2("3", "翠花", "女"));
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(fileName), Charset.forName("UTF-8"));
// 可通过比较器指定列的顺序
// 通过CsvBindByName注解的column属性,指定标题行的列名
HeaderColumnNameMappingStrategy<User2> strategy = new HeaderColumnNameMappingStrategy<>();
// 注意这里的key是指的标题行的列名
HashMap<String, Integer> columnOrderMap = new HashMap<>();
columnOrderMap.put("用户ID", 1);
columnOrderMap.put("用户名", 10);
columnOrderMap.put("性别", 100);
strategy.setColumnOrderOnWrite(Comparator.comparingInt(column -> (columnOrderMap.getOrDefault(column, 0))));
strategy.setType(User2.class);
StatefulBeanToCsv<User2> statefulBeanToCsv = new StatefulBeanToCsvBuilder<User2>(writer)
.withMappingStrategy(strategy)
.withApplyQuotesToAll(false)
.build();
statefulBeanToCsv.write(list);
writer.close();
}
|
1
2
3
4
| 用户ID,用户名,性别
1,张三,男
2,李四,男
3,翠花,女
|
读取方式
通过简单的写入写入的数据
① 简单的读取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| /**
* 简单的读取
* @throws Exception
*/
private static void csvReader() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
InputStreamReader reader = new InputStreamReader(new FileInputStream(fileName), Charset.forName("UTF-8"));
CSVReader csvReader = new CSVReaderBuilder(reader).build();
List<String[]> list = csvReader.readAll();
for (String[] strings : list) {
System.out.println(JSON.toJSONString(strings));
}
csvReader.close();
}
|
1
2
3
4
| ["用户ID","用户名","性别"]
["1","张三","男"]
["2","李四","男"]
["3","翠花","女"]
|
② 基于位置映射的读取
通过基于位置映射的写入写入的数据
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| /**
* 基于位置映射的读取
* @throws Exception
*/
private static void csvToBeanByPosition() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
InputStreamReader reader = new InputStreamReader(new FileInputStream(fileName), Charset.forName("UTF-8"));
// 不需要标题行,列的顺序通过列位置映射指定
ColumnPositionMappingStrategy<User> strategy = new ColumnPositionMappingStrategy();
String[] columns = new String[] { "userId", "userName", "sex"};
strategy.setColumnMapping(columns);
strategy.setType(User.class);
CsvToBean<User> csvToBean = new CsvToBeanBuilder<User>(reader)
.withMappingStrategy(strategy)
.build();
List<User> list = csvToBean.parse();
for (User user : list) {
System.out.println(JSON.toJSONString(user));
}
reader.close();
}
|
控制台日志:
1
2
3
| {"sex":"男","userId":"1","userName":"张三"}
{"sex":"男","userId":"2","userName":"李四"}
{"sex":"女","userId":"3","userName":"翠花"}
|
③ 基于CsvBindByPosition注解映射的读取
通过基于CsvBindByPosition注解映射的写入写入的数据
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| /**
* 基于CsvBindByPosition注解映射的读取
* @throws Exception
*/
private static void csvToBeanByPositionAnnotation() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
InputStreamReader reader = new InputStreamReader(new FileInputStream(fileName), Charset.forName("UTF-8"));
// 不需要标题行,列的顺序通过CsvBindByPosition注解的position属性指定
CsvToBean<User1> csvToBean = new CsvToBeanBuilder<User1>(reader)
.withType(User1.class)
.build();
List<User1> list = csvToBean.parse();
for (User1 user : list) {
System.out.println(JSON.toJSONString(user));
}
reader.close();
}
|
控制台日志:
1
2
3
4
| {"sex":"男","userId":"1","userName":"张三"}
{"sex":"男","userId":"2","userName":"李四"}
{"sex":"女","userId":"3","userName":"翠花"}
|
④ 基于列名映射的读取
通过基于列名映射的写入写入的数据
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| /**
* 基于列名映射的读取
* @throws Exception
*/
private static void csvToBeanByName() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
InputStreamReader reader = new InputStreamReader(new FileInputStream(fileName), Charset.forName("UTF-8"));
// bean的字段名称大写为标题列名
CsvToBean<User> csvToBean = new CsvToBeanBuilder<User>(reader)
.withType(User.class)
.build();
List<User> list = csvToBean.parse();
for (User user : list) {
System.out.println(JSON.toJSONString(user));
}
reader.close();
}
|
控制台日志:
1
2
3
| {"sex":"男","userId":"1","userName":"张三"}
{"sex":"男","userId":"2","userName":"李四"}
{"sex":"女","userId":"3","userName":"翠花"}
|
⑤ 基于CsvBindByName注解映射的读取
通过基于CsvBindByName注解映射的写入写入的数据
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| private static void csvToBeanByNameAnnotation() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
InputStreamReader reader = new InputStreamReader(new FileInputStream(fileName), Charset.forName("UTF-8"));
// CsvBindByName注解的column属性为标题列名
CsvToBean<User2> csvToBean = new CsvToBeanBuilder<User2>(reader)
.withType(User2.class)
.build();
List<User2> list = csvToBean.parse();
for (User2 user : list) {
System.out.println(JSON.toJSONString(user));
}
reader.close();
}
|
控制台日志:
1
2
3
| {"sex":"男","userId":"1","userName":"张三"}
{"sex":"男","userId":"2","userName":"李四"}
{"sex":"女","userId":"3","userName":"翠花"}
|
⑥ 基于列名转换映射的读取
通过基于CsvBindByName注解映射的读取写入的数据
使用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| public class MyCsvToBeanFilter implements CsvToBeanFilter {
@Override
public boolean allowLine(String[] line) {
// 过滤掉用户名为李四的行
if("李四".equals(line[1])){
return false;
}
return true;
}
}
/**
* 基于列名转换映射的读取
* @throws Exception
*/
private static void csvToBeanByColumnNameTranslateMapping() throws Exception {
String classpath = Thread.currentThread().getContextClassLoader().getResource("").getPath();
String fileName = classpath+"test/demo.csv";
InputStreamReader reader = new InputStreamReader(new FileInputStream(fileName), Charset.forName("UTF-8"));
// 指定标题列名和bean列名映射关系
HeaderColumnNameTranslateMappingStrategy<User> strategy = new HeaderColumnNameTranslateMappingStrategy<>();
// key:标题列名,value:bean的属性名
HashMap<String, String> columnMappingMap = new HashMap<>();
columnMappingMap.put("用户ID", "userId");
columnMappingMap.put("性别", "sex");
columnMappingMap.put("用户名", "userName");
strategy.setColumnMapping(columnMappingMap);
strategy.setType(User.class);
CsvToBean<User> csvToBean = new CsvToBeanBuilder<User>(reader)
.withMappingStrategy(strategy)
.withFilter(new MyCsvToBeanFilter())
.withIgnoreField(User2.class, User2.class.getField("userId"))// 忽略userId属性
.build();
List<User> list = csvToBean.parse();
for (User user : list) {
System.out.println(JSON.toJSONString(user));
}
reader.close();
}
|
控制台日志:
1
2
| {"sex":"男","userName":"张三"}
{"sex":"女","userName":"翠花"}
|
3. commons-csv